Background
Conversion is building the marketing automation platform of the future. Powering AI augmented email nurture, a new standard for lead scoring, and integrated product data in their workflows is no small feat and requires solving difficult technical problems. This article dives into how we designed and built the data connector and data synchronization platform — the component responsible for syncing millions of our customers’ most important business records in from and out to their CRM’s every day.
Architectural Considerations
Our urgency for the initial version of the platform and first connector (Hubspot) was astounding — all initial pilots were ready to try our product whenever the first version was ready. At startups, the winners are decided by iteration speed and decision making so the pressure was on.
While it would be easy to lean too far into “build fast and break things”, we prioritized reliability and robustness of the system, while secondarily optimizing for synchronization latency. At Conversion, we understand our customers trust us with some of their most critical business workflows and data, and it could be disastrous if we write the wrong data back to customer CRM’s or miss running an automation for a set of high intent prospects in a campaign.
With this in mind, we designed a system with built in retries, reconciling capabilities, and almost real-time data syncs.
Data Modeling and Orchestration
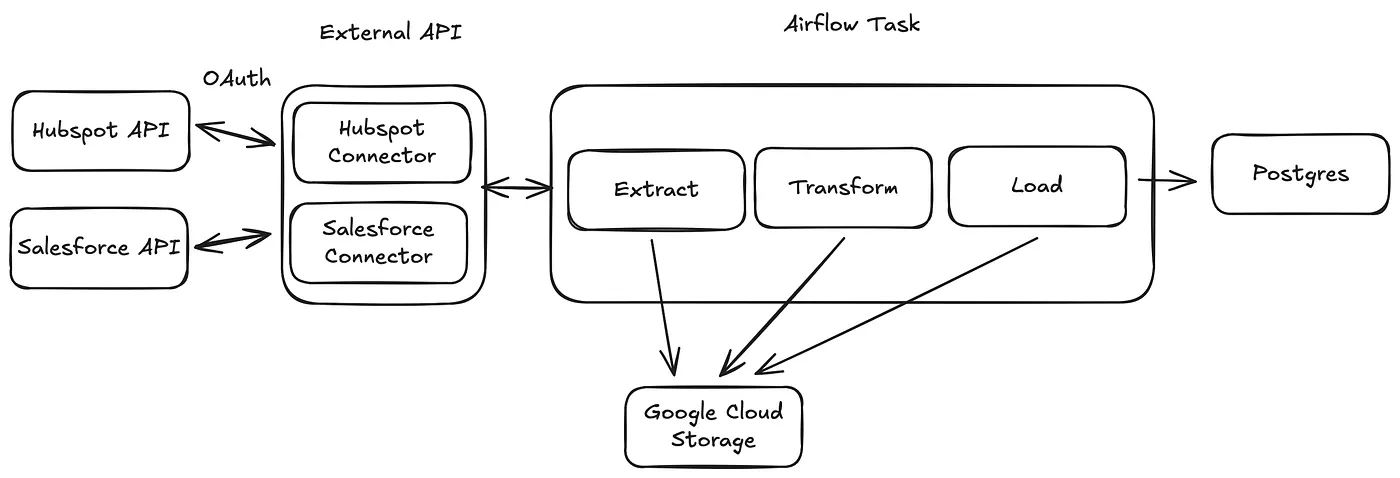
Data models within different CRMs have complex relationships and dependencies. Our first challenge was transforming and combining high cardinality, heavily interdependent data that varied based on the CRM into our opinionated data philosophy of how you should model marketing customer lifecycle data.
We opted with running our own in-cluster apache airflow instance. We essentially ran ETLs that would pull in, transform and load data from external connectors into our systems. This was lightweight, had built in system retries, and allowed us to schedule, reconcile, and debug specific nodes in the DAG’s without failing the entire run. This approach also allowed us to design data syncs around the dependencies of external providers — eg custom ordering of nodes based on the external providers entities.
One unique aspect of our implementation is that our backend systems are all written in Golang! In order to make this work, we use K8s operators running go binaries instead of Python.
How We Plug and Play Connectors
There are many sources of data that need to be synced into our systems (we haven’t even talked about data warehouses or our public API). It was top of mind to make it as easy as possible to integrate new connectors into our systems and maintain current ones!
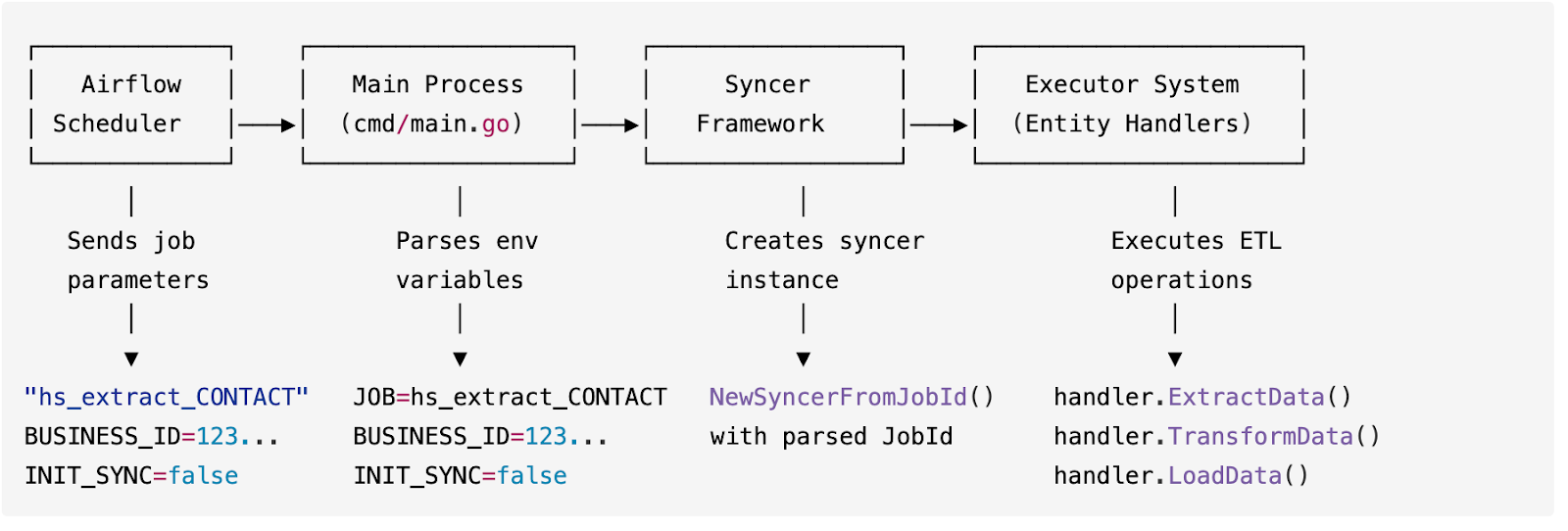
We leveraged Go’s interfaces to make an object hierarchy that abstracted away writing entire ETL scripts into implementing simple interfaces based on the external API’s. This works by making each DAG node instantiate an instance of the syncer configured with environment variables from that node. That syncer instance handles all generic ETL logic of parallelizing and looping through data. Finally, it calls interface functions that are CRM + external entity specific.
The end goal with the platform is that if you want to sync another entity for a specific CRM, the core syncing logic is re-usable and the developer only has to implement a interface specific for the data source.
Currently Supported CRM Connectors
For Hubspot we currently sync the following entities: Contacts, Companies, Deals, Calls, Meetings, Notes, Tasks
For Salesforce we currently sync the following entities: Accounts, Contacts, Events, Leads, Notes, Tasks, Opportunities
The tricky part here is that each of these entities could have thousands of custom fields per instance of an entity. Storing such high cardinality data to be easily and efficiently queryable is slated for a future blog post!
Scheduling and Reconciling
It’s inevitable that the syncer will have downtime and our goal is to recover as fast as possible. In order to make this a reality, we have a robust system of scheduling and reconciling.
Diving a bit deeper into the syncer — when a customer installs the Conversion app into their CRM we kick off the inital syncing job. After this, we run a continuous sync every two minutes. Within each of these syncs, we break down the data that needs to be processed into small chunks (<1 MB) which is then stored in a Google cloud bucket.
Chunking the large amounts of incoming data has a two distinct advantages: parallel processing and never losing progress. Whether it is a transient failure, node restart, or bug in a later stage of the syncer, we are able to restart processing for a specific chunk in under 10 seconds helping us drive down the syncing latencies even when there are errors.
With chunking, we now do the following whenever we face an error:
- Retry from the failed DAG node + chunk combination up to 3 times
- Page on-call Conversion engineer if a specific chunk fails after retries
- Reconcile all data from transient errors via a daily cronjob
Overall, this architecture has helped us drastically reduce the time to recovery and ensure customers don’t miss critical updates.
Looking Ahead
We hope this small peak behind the curtain at one of our most critical systems was insightful. We could write pages upon pages of implementation details but in the spirit of keeping the reading brief we’ve spared you guys many of the details that we’ve spent hundreds of hours contemplating!
Getting this far would’ve been impossible without the talented engineers at Conversion who maintain and continuously improve this living, breathing data synchronization system. Especially huge shoutouts to Swamik Lamichane and Naasir Farooqi for being main contributors on the project.
If you love tackling interesting technical problems like the ones in this article, Conversion is hiring! We’re constantly working to build new features, improve reliability, and scalability. Please reach out if you’d like to join us on the mission of building the future of marketing.